 Darius Mortazavi
Darius Mortazavi
Today's issue of The Diff is brought to you by Dover, an applicant tracking system.
The Supply Chains of Bits and Atoms
Economic activity, in its most abstract sense, is just finding, moving, processing, and selling atoms or their electrons in the form of bits.[1] This means we can model the flow of value in the economy by looking at the flows of those things as they pass through the entities that transform them. And that should teach us something, because some of the most interesting companies are the ones that can repurpose whatever value-creating activity they're best at across many concepts.
This, like many other kinds of business, is relatively easy to see in the software industry—an online video company can sell the same content as a subscription product or as a source of eyeballs for ads, but can also edit it into a form of marketing. This is less obvious but sometimes more powerful in the physical world. In a very classical physics way of looking at things, bits can be thought of as packets of electrons flowing through a lattice structure of relatively large atomic nuclei. A basic but practical model for thinking about that transport is the Drude model, which, fortunately, is fairly easy to visualize:
(Via Make a GIF)
In the last half century we’ve discovered a seemingly infinite number of ways to combine those bits to create an ever expanding number of digital products and services. There are obviously a lot of reasons for this, but the ability to scale isn’t strictly a function of funding and total addressable market—it's also constrained by very real physical limitations. From this perspective, information businesses benefit from a very unique feature that “bits-as-a-feedstock” provides: bits can flow down (mostly) the same wires, regardless of the information they store, can be separated upon arrival at approximately zero cost, and can be transported at the speed of light. In short, bits are an extremely homogeneous input to the information economy.
This homogeneity enables a shared infrastructure that frequently defines the unit economics for information-based businesses: decreasing marginal costs as they scale. Of course, decreasing marginal costs like this are not unique to the information economy. Plenty of businesses benefit from economies of scale. But none have scaled to the same magnitude, and with the same velocity, as software. A subscale manufacturer might struggle to hit 5% margins while their larger competitors comfortably rest at 15%, but some tech companies have had to undertake a simply heroic level of moonshot R&D investment and employee perks to keep their margins from relentlessly drifting up past 50%.[2]
Maybe it should come as no surprise that the closest analogy here is just one level up from electrons: atoms! The energy, chemicals, and materials industries form the basis of the physical economy, that which we build everything with.
The thinking here is pretty simple: you could say that bulk chemicals and materials are effectively "packets" of atoms, in the same way that bits are packets of electrons. And these atom-packets do offer some homogeneity. Even though crude oil is generally referred to as one thing, it’s actually a mixture of disparate products, all of which can be immediately consumed for their immediate fuel value or processed for their material value—all you need is a distillation column at the far end to handle their separation. (Which is a cost that someone must bear, and one that information businesses do not have to.) If you squint, oil refineries end up being the world-of-atoms equivalent to Google or an HFT firm, absorbing a vast amount of raw material and outputting usable forms.[3]
But things get even more tricky from here. As you work your way down physical economy value chains, your ability to leverage shared infrastructure decreases, consumption can’t be quite as granular, and transport speeds are slow because fluids don’t flow at the speed of light. The net effect is that you can’t just build a chemical plant anywhere—it needs to be near physical feedstock sources, affordable skilled labor, and appropriate infrastructure.[4]
A really simple example of this pseudo-homogeneity at work is the production of LNG. The taxonomy overlaps a bit here, but here’s the general idea: raw natural gas comes from the well, most of the heavier stuff (like ethane, butane, and so on) is removed, leaving behind the kind of natural gas that we liquefy. A lesser known but critical input to that liquefaction is natural gas itself—something has to power the turbine that re-compresses the refrigerant we evaporated to cool natural gas to cryogenic temperatures, and that power frequently comes from the combustion of natural gas.
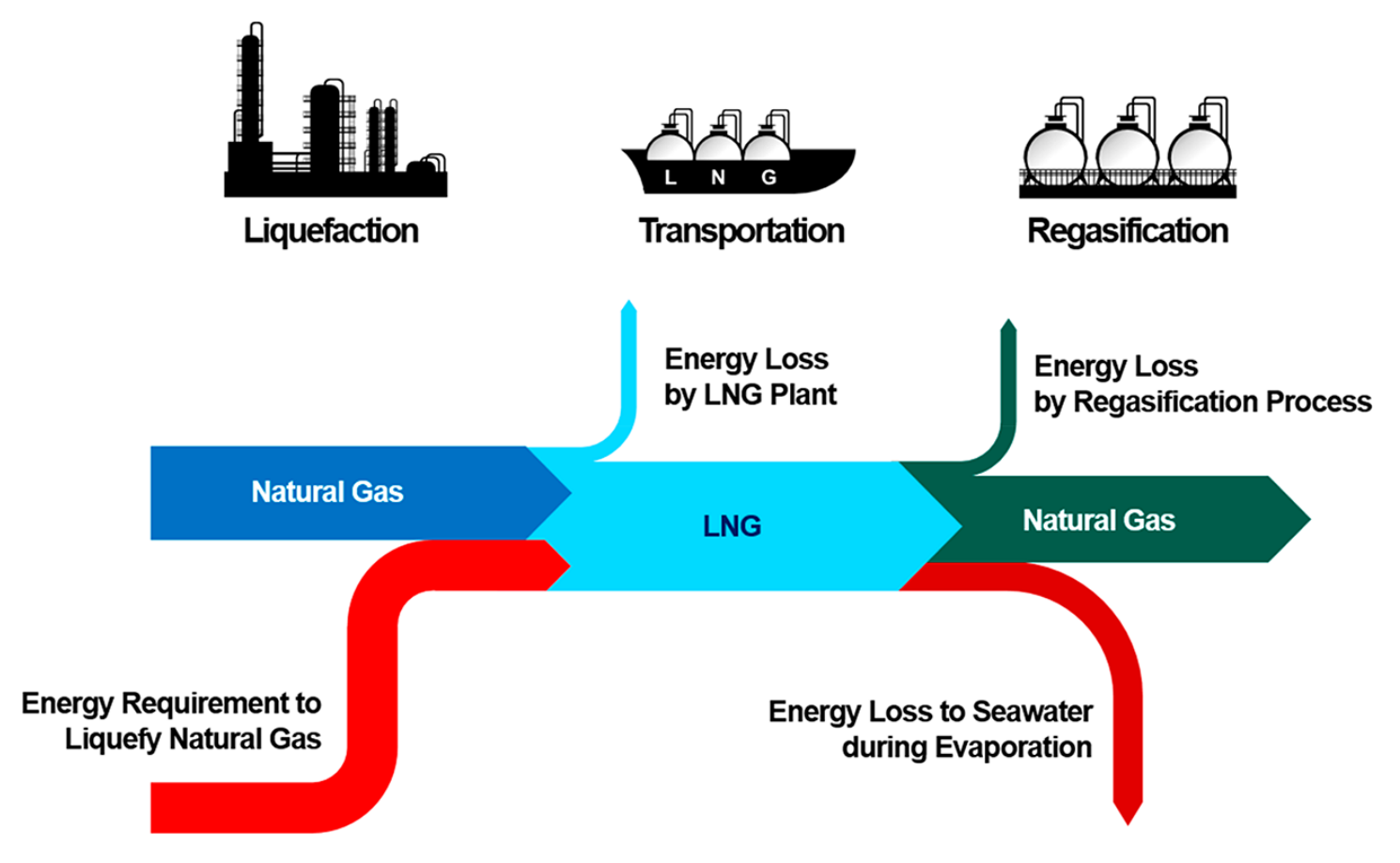
(Via this paper.)
But you can take the analogy a lot further than that. Let’s say that your raw material is credit card transaction data. The raw data isn’t particularly valuable, but if you’re able to classify those transactions into categories that the average person can understand, you can market that transformed data to consumers in the form of a budgeting app. Similarly, raw natural gas straight from the well is also not particularly valuable, but if you knock out the nasty stuff and fractionate it you could market that natural gas (which is a lot more like methane at this point) directly to consumers’ homes for the sake of heating.
As Diff readers surely know, credit card transaction data can be transformed for far more valuable applications—if you were to combine it with other data, like email receipt data, and do some processing, you might be able to market it for hedge fund consumption. On its own, it's a useful market research and benchmarking tool for companies. Natural gas has similar opportunities: if you instead chose to use some of that natural gas to spin a refrigerant compressing turbine, you can drive a cycle that cools other natural gas to -260°F, making it a liquid that opens up new markets.
On its own that data isn’t worth very much because it’s not useful in its current form. If you want to make use of it, you’ll need to combine it with other data, like email receipts, web scraping, internal company metrics, etc.; then do some more processing, and package it up nicely so it can drive decisions. Similarly, if your raw material is natural gas, it’s only worth its fuel value unless we do something to it. Of course, most of the world’s natural gas is used for fuel, but we always have the option to upgrade its value.
For example, we could combine it with water (or, more accurately, steam) to produce a mixture of hydrogen and carbon monoxide (a mixture typically referred to as syngas). That mixture could then go on to make liquid fuels via Fischer-Tropsch synthesis, or it could be catalyzed to produce methanol (which is mostly converted into acetic acid, which is one of the most common precursors to paints, coatings, and adhesives—and, more abstractly, as the solvent used in the production of terephthalic acid, a precursor to the world’s most prolific single-use plastic: PET).
The similarities here are clear: a single raw material with a shared infrastructure undergoes processing by various parties, and it is ultimately transformed and combined to satisfy an ever increasing number of unique applications.
But there’s a difference between bits and atoms that we can’t ignore. At one level, the chemicals industry is using a small number of distinct feedstocks to make an insane variety of end products. Information businesses are tricky in this mode. In one sense they have just one feedstock, bits. In another sense, they have the most diverse feedstock, because every useful bit of information is its own unique thing. This is not the case with atoms—we're not just talking about electrons here, now we’re talking about protons and neutrons. So we end up with a finite number of feedstocks, leading to a larger number of intermediate material outputs, which themselves can be combined in an infinite number of ways.
And that ultimately ties the supply chains together. Raw materials tend to get exploited by their relative ease of extraction, so the fundamental cost of getting them goes up slowly over time. At the same time, extraction also gets more efficient for a given deposit; one reason known oil reserves have tended to go up over time is that more efficient drilling makes more deposits economical to use (higher prices also help here). So, over time, a shortage of a particular set of atoms turns itself into a shortage of bits about where the best deposits are located and what the best ways are to extract them. The two abstract supply chains are always entangled.
You can add Joules to the model as described above, or you could model all of economic growth in terms of extracting and transforming energy up to about 1970—before we started selling electrons as bits, in the world where all energy was being directly applied to atoms (moving them in the case of transportation, transforming them in manufacturing, cooling them, etc.) ↩︎
There are precedents for this: corporate R&D spending ramped up in the 1930s, when corporate profits were a political issue; there was, for example, a tax on corporate profits that weren't distributed as dividends for a while during this period. If a corporate capital allocator's model is that taxes fluctuate up and down over time, high taxes or the risk thereof are a subsidy to long-term R&D whose payoff might happen in a more friendly regulatory regime. ↩︎
As in many other cases, there isn't a strict atoms-and-bits division in either case; refineries need plenty of software and human capital to operate at maximum efficiency, while Google needs to operate plenty of physical hardware to support the software business. Just like in other cases where a company has a comparative advantage at one thing and thus grows to the point that all of its problems come from things it's relatively worse at, any bits-first company will run into atom-limited scaling problems—witness cloud hyperscalers being slowed down by the unavailability of certain varieties of processed sand from Taiwan—while atoms-first companies need to navigate the efficient frontier between human supervision and full automation. ↩︎
Unless we decentralize material production, which is interesting, but generally up against concepts like geometric scaling that have served atom-first companies well. In any case, it could be fun to explore decentralized material production as an argument for a CO2 based economy. In a future world where we want to transport matter, and energy is free, the best and cheapest shared infrastructure is the air, otherwise you’ll be stuck piping and separating at all endpoints. A world with cheaper transportation for humans, energy, and materials is a world where manufacturing is concentrated in the least desirable pieces of real estate that aren't actively uninhabitable. And even though this is a hypothetical world where manufacturing is far more efficient, it's also probably a world where, paradoxically, the services sector is even more dominant and cities are even more specialized: one estimate claims that roughly half of the space in a typical downtown is devoted to moving or storing cars, which means that cities that use this space more efficiently can support much higher density, and higher land prices. And while this will price more industries out, it will also mean that the survivors get even bigger agglomeration benefits. ↩︎
A Word From Our Sponsors
Dover is making world-class recruiting accessible to all.
Hiring the right talent is critical to any company’s success—especially for startups. Dover makes it easy for any company to run a world-class recruiting process, at no cost to the company.
Dover’s free ATS (Applicant Tracking System) is designed for founders and hiring managers to consolidate all their recruiting in one easy place. No more disorganization, dropped candidates, or chaotic scheduling emails.
Review applications at lightning speed, post to 100+ job boards (including free job posts on LinkedIn), send next steps to candidates in one click, create a beautiful careers page in seconds, and more.
Recruiting, simplified.
Elsewhere
7nm
A teardown reveals that Huawei's new Mate 60 Pro phone uses 7nm chips fabricated by China's SMIC. This puts China roughly five years behind the US-controlled chip supply chain; the Apple A12, announced in 2018, also used 7nm chips. On the other hand, that may be a low estimate of the gap: "It is unclear how many units of the new device Huawei intends to produce. The Mate 60 Pro sold out almost immediately and appears to have been available in limited quantities." One possibility is that Chinese chipmakers are able to produce 7nm chips, but not at economical yields—it may suit the Chinese state's goals to a) subsidize what would otherwise be momney-losing chip manufacturing (which the US did as early as the 1960s) and b) to highlight the mere existence of these chips even if they're not widely available. The closer the chip gap appears to be, the more important sanctions are and the less of a difference they make.
New Yahoo
One of the jokes in Project Boing ;), the Yahoo-inspired novel, is that Yahoo likes to launch projects that recreate the magic of fantasy sports, which never quite took hold. It's interesting to read this Axios blurb on Yahoo's turnaround under PE ownership in light of this: the company has acquired a social investing product (Yahoo! Sports Fantasy Football for Stocks!) and a sports betting app (Yahoo! Sports Fantasy Football with usage-based monetization!), as well as other deals (StrictlyVC, Factual) that don't fit the pattern. The most illuminating problem Yahoo has is that it's hard to describe what the business is, or what makes it special. One explanation for this is that Yahoo was an adaptable business that evolved fast for a very important half-decade of the Internet's existence, but eventually reached a point where the rest of the Internet iterated at a faster pace than it did. So the company was increasingly good at serving a narrow demographic of people who didn't change their habits that much. In some categories, that's a big enough advantage to build a business: Yahoo can justify a big news operation because it has captive traffic, and that news can also bring in outside readers as a bonus. But it's hard to run a business strategically when the correct strategy is dictated by other companies that captured search and social distribution first and won't let it go.
Red Teams and AI Unit Economics
Forbes has a good piece on the "red teams" at major AI companies, which try to get models to do things they're not intended to do. As models get more complex and their behavior gets harder to predict, moderating them becomes more of a brute-force project. It's clearly a nonlinear cost, since the models and the users are always getting smarter, and emergent behavior between two agents who are a) intelligent, or at least intelligent-acting, and b) who exhibit very different kinds of intelligence, can be hard to predict. One fun question to ask is what the scaling laws look like for moderation, and how those compare to scaling laws around running small-scale models that are less hardware-constrained. If there's a use case where an open-source model running on a local machine can produce better-than-human performance at generating some kind of content, it doesn't matter that much if the best models are more restrained in their output. Meanwhile, the AI model developers who do care about moderation will have an extra cost that scales nonlinearly, both in terms of money and in terms of time required. And it's an open question as to what the steady state looks like; the models are partly being selected to say nice things, but they're also being selected for Straussianism. Which, of course, will make them much more fun to talk to.
Horizontal Expansion
Spotify's foray into pocasts hasn't had the returns the company expected ($, WSJ), as celebrity exclusives a) haven't driven the subscriptions growth the company hoped for, and b) as exclusives, also don't produce enough ad inventory to be viable. One of the paradoxes of media is that, unlike many other categories, the heavier a consumer the end customer is the worse the product they're going to use: if ad revenue is measured per listener-hour and recurring revenue is measured per subscriber-month, there's a usage threshold after which the company wants its heaviest users to convert to a mdoel where their listening is periodically interrupted by ads.
Spotify's podcast growth ties into the fact that audio is a unique consumption pattern: people often listen while doing something else (driving, chores, working out, etc.), but can't use multiple audio apps at once. This strongly encourages audio companies to go horizontal; they get more data and better retention if they maximize share-of-ear. But that sometimes means making expensive mistakes, especially when a new category's growth in listener time is faster than its growth in revenue.
Private Markets
The London Stock Exchange Group is trying to build a market in private company stock ($, FT). These markets are notoriously hard to build: every market needs active buyers and sellers, and low enough information asymmetry that people can transact without worrying too much about adverse selection. LSE is trying to reduce the information asymmetry by giving users a way to share data, but this doesn't fully solve the liquidity program. In general, trading in private company markets is extremely skewed towards a handful of names; the first iteration of this market in the US was mostly devoted to trading shares of Facebook before its IPO. (Disclosure: currently long META.) When that went away, the network unwound for a while. In the absence of a company like that, it's very hard to bootstrap the market into existence. There may be some volume, as opportunistic hedge funds buy and early employees and investors diversify, and this kind of market is a nice complement to a more traditional exchange—if people are used to trading shares through the LSE, a Nasdaq listing is less likely. So, on the one hand, it's an impressive way to address a long-term strategic threat. On the other hand, there's a lot of short-term difficulty ahead.
The Diff previously covered LSE Group and the complexities of its diversification strategy ($).
Diff Jobs
Companies in the Diff network are actively looking for talent. A sampling of current open roles:
- A data consultancy is looking for a senior data scientist with prior experience in marketing data science and e-commerce. (NYC)
- A systematic hedge fund is looking for researchers and portfolio managers who have experience using alternative data. (NYC)
- A well funded seed stage startup founded by former SpaceX engineers is building software tools for hardware engineering. They're looking for a full stack engineer interested in developing highly scalable mission-critical tools for satellites, rockets, and other complex machines. (Los Angeles)
- The leading provider of advanced options analytics — “the ASML of options trading” — is growing rapidly, very profitable, and looking for a generalist who can excel in chief of staff and business development functions. A trading, quant, or similarly technical background is a big plus. (Connecticut, NYC)
- A successful crypto prop-trading firm is looking for new quantitative developers with experience building high-performance, scalable systems in C++. (Remote)
Even if you don't see an exact match for your skills and interests right now, we're happy to talk early so we can let you know if a good opportunity comes up.
If you’re at a company that's looking for talent, we should talk! Diff Jobs works with companies across fintech, hard tech, consumer software, enterprise software, and other areas—any company where finding unusually effective people is a top priority.