
Daloopa: Data-to-Information Accelerant
One thing hedge fund analysts have in common with data scientists is that both of them have well-paid, high-status jobs, despite the fact that a significant component of these jobs is literally data entry. Yes, if you work at a hedge fund you may find yourself teasing out a unique thesis about a company's long-term unit economics; yes, if you do data science you'll sometimes apply clever algorithms to develop amazing insights about human behavior. And, in both jobs, you'll spend part of your time manually typing in or looking at data, reformatting things so they're compatible with what you've already built, and double-checking your work to make sure your conclusions aren't novel because of a mistake you made.
Wrangling all of the world's data into usable formats is going to be a lengthy process. In part that's because "usable" is a vague term, since there are so many different use cases. An academic studying software economics, an IRS agent checking on a software company's tax returns, a CFO figuring out the company's capital needs, and a hedge fund analyst deciding whether or not to buy the stock will all care about how much a given company makes, but they're all defining it differently, and in some cases they use the same terms in completely different ways ("profit" means something different to economists, investors, and tax collectors, for example—to the point that some things that makes profits-according-to-the-IRS go down will make profits-according-to-economists-and-analysts go up).
So the overall data cleaning problem won't get fully solved any time soon, but in some domains it's getting closer. Daloopa is a company that does automated financial model building, focused on the investment analyst market, and it's a good way to understand what comes next when these data problems get more tractable.
(Disclosure: Readers of The Diff probably recognize Daloopa from their ads in this publication. But the disclosure could just as easily go the other direction: I think Daloopa is a cool company; given the usual work hours at hedge funds, if I'd had it when I was at a fund it might have cut 10% off my work time—or, to put it in more meaningful terms, might have doubled my non-sleep leisure time.)
The basic idea of Daloopa is to take companies' public disclosures—10-Ks, 10-Qs, earnings releases, investor presentations, and (coming soon) conference calls—and work them into consistent spreadsheets. This is a nontrivial part of analysts' jobs, too; one reason earnings season is so hectic is that analysts are updating models with all the data companies have released.
It's worth thinking about what this workflow looks like, and why it looks that way:
The most important numbers typically make it into headlines basically instantaneously; there is no longer an edge in being the first person to read Netflix's net subscriber additions, or their guidance.
Services like FactSet and Bloomberg will update models, generally on a delay, but they don't include every indicator, and for some of the company-specific ones, they're not necessarily accurate. (One data provider I used to track hotel companies, for example, did not draw a distinction between "North America" unit revenue and "US" unit revenue, which are sometimes very different numbers!)
The point of fully updating a model is twofold. First, there are some theses that play out in low-level performance indicators rather than the high-profile numbers; if you're following a company that's a growth story, but you're obsessed with the leverage they're getting on sales and marketing spending, the headlines may not tell you much. Second, sometimes the story changes. For most companies, in most quarters, investors know roughly what to pay attention to, but sometimes the right metric changes. There was a period of a few quarters in 2013 where Facebook's desktop advertising revenue number went from the only thing that mattered to being a basically irrelevant detail. Stocks generally react most strongly the day they report, but when the story around a company changes, one indication of this is that the price moves more in the days after the report, as investors have had a chance to digest what's changed.1
Daloopa makes this process faster by using a combination of manual data entry and machine learning. There are several layers of productivity improvement here: people can get extremely quick at tracking down and entering the number that matters (there was a brief period where you could generate reliable after-hours alpha by opening the Priceline earnings release, scrolling two thirds of the way down the page, taking the midpoint of their bookings growth guidance, and adding 7 points to it; the company reported late in the quarter, and was religious about guiding conservatively). Once the metrics are established for a company, it's fairly straightforward to automate the process of extracting them—textual details like "units sold were x, up y% year on year" constitute a built-in error check for textual data. And over time, this work creates a library of techniques for extracting data in different formats, whether they're tables in SEC filings (easy), standardized bullet points in PDFs (still pretty easy, but getting trickier), or textual commentary in a 10-K or 10-Q (easy to get this to 99% accuracy, much harder to get to 99.99%).
Getting accuracy right matters, because a substantial chunk of the data-entry process consists of double-checking. It's a general rule in stock picking and data science that the more interesting the conclusion, the more likely it's a mistake. There are simply more possible errors out there than novel discoveries, so the right bet is to be cautious. But constant error-checking imposes overhead, both in terms of time spent and in terms of distraction; if you're thinking about whether or not you calculated adjusted EBITDA the way the company did, you're not thinking about which way that number is heading or why.
Two quarters ago, Daloopa was tracking 200 companies and updating the models within 24 hours of a new earnings release. Now they're at 3,000, growing 70-100 each week, and updating within two and a half hours. The goal is to track every public company, and update within half an hour. That kind of improvement can only come from compounding the library of data-extraction tools.
There's something undeniably meditative about building a financial model by hand, entering every quarter's data one spreadsheet cell at a time. On the other hand, there's something undeniably lame about making an excuse for all that busywork—instead of two hours of mandatory meditative data entry, it might be more cost-effective to spend fifteen minutes using Calm or Headspace and then push a button to instantly build your financial model.
For many companies, analysts develop a sort of oral culture with folk wisdom about which metrics matter and where to find them. There are companies that reliably give important guidance in the first bullet point of every earnings release, others that defer it until their earnings call, and some that drop those details in their 10-Q or 10-K. But if a company regularly releases a number, then in principle tracking it should be automated; it might be a fun puzzle, or an impressive answer at a job interview, to rattle off every obscure disclosure a company makes. But it's not really something that adds value, just something that prevents sloppy disclosure from subtracting value.
What does add value is analysis, and getting data is the big barrier to this. One of the things Daloopa is increasingly working on is industry dashboards that track granular disclosures across companies to see what's developing. This is somewhat analogous to stock screening, in that it's a way to grab comparative data on a large set of companies. But there are two issues with stock screening: first, they require you to come up with a theory in advance and then see if there's confirming evidence, whereas the best trades are often the ones where what's happening at the company is something you never would have thought of on your own. Second, they impose arbitrary cutoffs, and since people like to use round numbers, those cutoffs can hide some interesting trends; there's probably a lot of value in the stocks that trade at the 11th percentile of price/book value or are in the 89th percentile for momentum, and there are no doubt some very compelling growth stories among companies putting up 19.5% revenue growth given how many people screen for 20%+.
Doing cross-industry comparative analysis is very data-intensive, and it often doesn't produce interesting results; sometimes, grabbing years of data for a dozen different companies just shows you that all dozen of them are subject to the same external forces. But if all the data is easy to grab, you can do some interesting things, like comparing the inventory composition across the auto sector to see who's struggling with supply chain issues and who's struggling with demand instead:
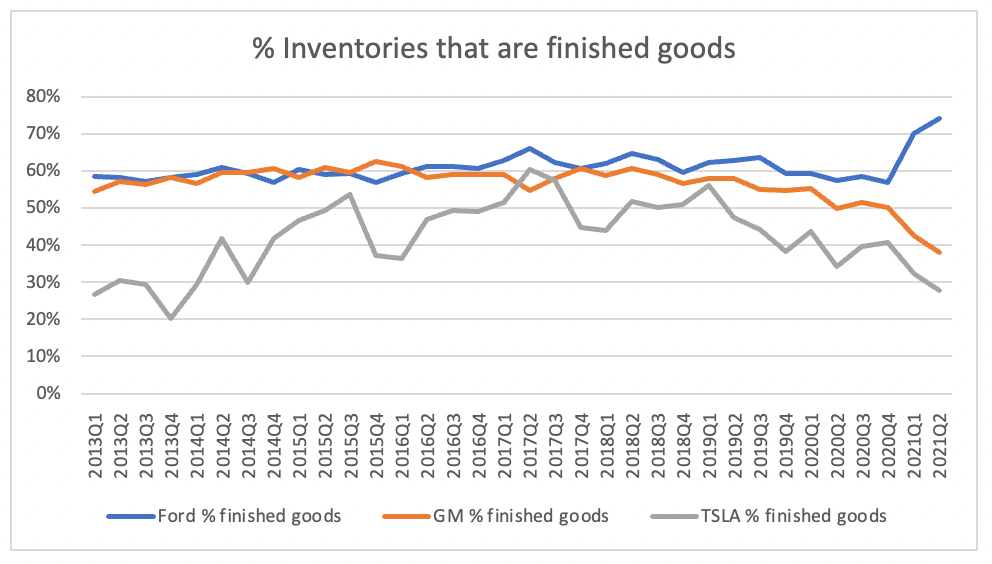
No look at a labor-saving enterprise software product would be complete without asking about the incentives for the laborers themselves: no one wants to buy something that puts them out of a job. At hedge funds, that can be particularly acute, because they generally have a flat organizational structure; the person making the purchasing decision may not be the analyst, but is probably the person the analyst reports to. So if analysts are going to get automated into unemployment, they'll lobby against automation.
The pitch for Daloopa is that analysts can either cover more names to equivalent depth or cover the same set of companies in more depth. If data is a complement to insight, then commoditizing the data makes insight more valuable. There are a few ways the product makes life easier for analysts. The most obvious is giving them a pre-built model for the companies they follow, but Daloopa is also close to launching the "Differencer," a product that takes an existing model and a) identifies all the metrics that aren't being tracked in it, and b) that automatically links hard-coded numbers to their original source. This can be a way to refresh a perspective on companies, and to see if they've started releasing a number that they didn't previously.2
As someone whose job is to produce conclusions that are hopefully interesting, novel, and based on real-world data, I'm always excited when more of the world's information gets accessible. There's a lot more to opening up the world's data than automatically converting corporate disclosures into Excel documents (or, really, converting them back—every earnings season involves countless labor-hours from investor relations teams that copy numbers from spreadsheets into powerpoints, and then even more hours from analysts who copy them out of presentations and back into Excel). But it's a valuable space, and a good proof of concept: over time, all the information hidden in hard-to-parse formats or clunky legalese will be rendered in a format that makes it easier to analyze.
Elsewhere
Covid Zero vs Ο-Variant
Some Chinese cities are quarantining domestic travelers in order to control the spread of the omicron variant ($, Nikkei). Omicron is an especially interesting challenge for China, because right now it appears that the variant is both more contagious and less harmful than other variants. Another way to look at this is that if omicron had come first, China might not have pursued a Covid-zero approach. But now that the state's legitimacy is partly tied to the government's handling of Covid, it's hard to reverse—especially because Covid-zero means that China's population is unusually vulnerable, because they don't have a large population with antibodies like most of the rest of the world.
Covid Hormesis
Restaurants are much better prepared for omicron-related shutdowns than they were for round one of Covid. Some of this is for the obvious reason that they've shifted more of their model to delivery, and found digital customer acquisition channels instead of relying on walk-in traffic. But there's also the meta-level way they've changed their models: Covid forced many restaurants to think of themselves as having multiple sales channels, and to get to the point where they could at least survive without using a physical location, even if that survival was less lucrative than their prior existence. This naturally benefits the big delivery platforms, which have a lot more market power than single-location restaurants they deal with. On the other hand, those restaurants were already used to relying on a counterparty with more market power than they had—their landlords. One way to look at this is that any given restaurant is closer to a monopsony now, because they only need to strike a bargain with one monopolist at a time; if rent is too high, they can move and focus their model more on delivery, and if delivery fees are too high, they can aim for walk-in traffic instead.
Life on Planet Baumol
A few years ago, there were regular stories about the tight labor markets in towns close to shale plays—fast-food workers were earning double minimum wage and other workers were doing even better. Fracking is not quite so exciting lately, but the growth of logistics has created similar dynamics elsewhere. The WSJ highlights the booming job market in Louisville, where a UPS hub has put upward pressure on wages for everything else ($). Baumol's cost disease is often cited as a negative, since it means that productivity in one sector can push up costs everywhere else. But it's also a form of economic redistribution: once a part of the economy reaches the point where it can reliably generate above-average returns on capital, with unskilled labor as an input, that sector puts a floor on wages, and ends up sharing its economic upside with every worker close to the bottom of the distribution.
The Right Amount of Fraud
The Secret Service says Covid relief fraud may have been as high as $100bn ($, WSJ). That's around 3% of total Covid relief spending. I wrote last year about the optimal amount of fraud in general, and for Covid offsets in particular ($), and argued then that 1) we should expect some fraud if spending is aggressive enough, and 2) for various reasons, it won't be a catastrophe. For example:
Some crimes are premeditated, and some are opportunistic. In this case, all of the fraud is opportunistic because the opportunity came into existence quite suddenly. Opportunistic crimes are common, but they’re usually small, and because the criminals are inexperienced they’re easier to catch. Longer-term policies can lead to bigger frauds, often by compounding: a bit of fudging initially, more fudging to cover it up, and growth from there.
Any big spending project will have some waste involved, and it's important to get most of it to its intended targets. But the fraud cost in percentage terms was impressively low. When credit cards were first introduced in the "Fresno drop" in 1958, Bank of America modeled a 4% delinquency rate but ended up with a 22% rate, since criminals quickly figured out how to steal cards and misuse them. For a brand new program that was literally intended to give away free money as quickly as possible, a 3% fraud rate starts to look pretty good.
Selective Disclosure
China’s Ministry of Industry and Information Technology will stop collaborating with Alibaba on cybersecurity for six months to punish the company for not disclosing the Log4j bug ($, WSJ). Alibaba was stuck between two standards: the expectation for software vulnerabilities is to privately report them to the entity that can fix them, and only disclose them publicly once the fix is ready, but MIIT wants researchers to disclose vulnerabilities to it right away. There is a generous reading of this, in which MIIT wants to be proactive about helping Chinese Internet companies keep themselves secure from fraudsters. There are other reasons to want preferential access to zero-days, though.
In practice, this digestion process usually consists of someone figuring out a new way to think about the company, trading accordingly, and then telling everyone they can about what they've learned. Stay tuned for future posts on other parts of the buy-side gift economy. ↩
It can also be a way to see if they stopped disclosing something the analyst didn't track. It's informative when companies change their disclosure—usually, whatever they decide to stop talking about is something that's started looking bad—so even if the metric didn't matter before, it matters when it's gone. ↩